#39: Faster Feedback Systems – A Continuous Integration Example
Welcome to the 39th post in the relatively randomly recurring rants, or R4 for short. Today’s post picks up where the previous post #38: Faster Feedback Systems started. As we argued in #38, the need for fast feedback loops is fairly universal and widespread. Fairly shortly after we posted #38, useR! 2022 happened and one presentation had the key line
Waiting 1-24 minutes for a build to finish can be a massive time suck.
which we would like to come back to today. Furthermore, the unimitable @b0rk had a fabulous tweet just weeks later stating the same point debugging strategy: shorten your feedback loop as a key in a successful debugging strategy.
So in sum: shorter is better. Nobody likes to wait. And shorter i.e. faster is a key and recurrent theme in the R4 series. Today we have a fairly nice illustration of two aspects we have stressed before:
Fewer dependencies makes for faster installation time (apart from other desirable robustness aspects); and
Using binaries makes for faster installation time as it removes the need for compilations.
The combined effects can be staggering as we show below. The example is motivated by a truly “surprising” (we are being generous here) comment we received as an aside when discussing the eternal topic of whether R users do, or do not, have a choice when picking packages, or approaches, or verses. To our surprise, we were told that “packages are not substitutable”. Which is both demonstrably false (see below) and astonishing as it came from an academic. I.e. someone trained and paid to abstract superfluous detail away and recognise and compare ‘core’ features of items under investigation. Truly stunning. But I digress.
CRAN by now has many packages, slowly moving in on 20,000 in total, and is a unique success we commented-on time and time before. By now many packages shadow or duplicate each other, reinvent one another, or revise/review. One example is the pair of packages accessing PostgreSQL databases. There are several, but two are key. The older one is RPostgreSQL which has been around since Sameer Kumar Prayaga wrote it as a Google Summer of Code student in 2008 under my mentorship. The package has now been maintained well (if quietly) for many years by Tomoaki Nishiyama. The other entrant is more recent, though not new, and is RPostgres by Kirill Müller and others. We will for the remainder of this post refer to these two as the tiny and the tidy version as either can been as being a representative of a certain ‘verse’.
The aforementioned comment on non-substitutability struck us as
eminently silly, so we set out to prove just how absurd it really is. So
about a year ago we set up pair of GitHub repos with minimal code in a
pair we called lim-tiny
and lim-tidy.
Our conjecture was (and is!) that less is more – just as post
#34
titled Less Is More argued with respect to package
dependencies. Each of the repos just does one thing: a query to a
(freely accessible but remote) PostgreSQL database. The tiny version
just retrieves a data frame using only the dependencies needed for RPostgreSQL
namely DBI and
nothing else. The tidy version retrieves a tibble and has access to
everything else that comes when installing RPostgres: DBI, dplyr, and magrittr – plus
of course their respective dependencies. We were able to let the code
run in (very default) GitHub Actions on a weekly schedule without
intervention apart from one change to the SQL query when the remote
server (providing public bioinformatics data) changed its schema
slighly, plus one update to the action yaml code version. No other
changes.
We measure the time a standard continuous integration run takes in total using the default GitHub Action setup in the tidy case (which relies on RSPM/PPM binaries, caching, …, and does not rebuild from source each time), and our own r-ci script (introduced in #32 for CI with R. It switched to using r2u during the course of this experiment but already had access to binaries via c2d4u – so it is always binaries-based (see e.g. #37 or #13 for more). The chart shows the evolution of these run-times over the course of the year with one weekly run each.
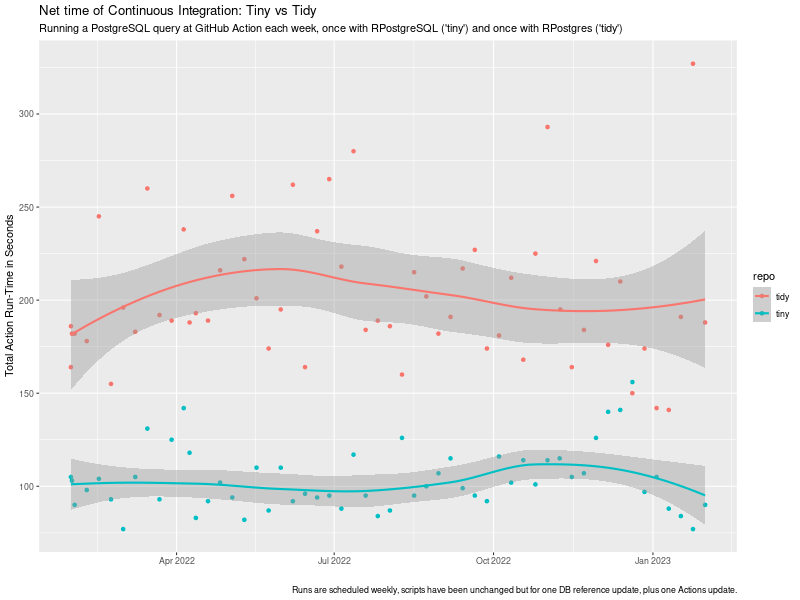
This study reveals a few things:
- “Yes, Veronica, we have a choice”: one year of identical results retrieving a data set via SQL from a PostgreSQL server. We can often choose between alternative packages to get (or process) our data.
- There is a Free Lunch (TM) here: RPostgreSQL consistently dominates RPostgres when measured in CI run-time for the same task.
- While there is (considerable) variability (likely stemming from heterogenous setups at GitHub Action) the tiny approach is on average about twice as fast as the tidy approch.
- You do have a choice. Would you rather wait x minutes for CI, or 2x?
The key point there is that while the net-time to fire off a single PostgreSQL is likely (near-)identical, the net cost of continuous integration is not. In this setup, it is about twice the run-time simply because ‘Less Is More’ which (in this setup) comes out to about being twice as fast. And that is a valid (and concrete, and verifiable) illustration of the overall implicit cost of adding dependencies to creating and using development, test, or run-time environments.
Faster feedback loops make for faster builds and faster debugging. Consider using fewer dependencies, and/or using binaries as provided by r2u.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.