#13: (Much) Faster Package (Re-)Installation via Binaries
Welcome to the thirteenth post in the ridiculously rapid R recommendation series, or R4 for short. A few days ago we riffed on faster installation thanks to ccache. Today we show another way to get equally drastic gains for some (if not most) packages.
In a nutshell, there are two ways to get your R packages off CRAN. Either you install as a binary, or you use source. Most people do not think too much about this as on Windows, binary is the default. So why wouldn't one? Precisely. (Unless you are on Windows, and you develop, or debug, or test, or ... and need source. Another story.) On other operating systems, however, source is the rule, and binary is often unavailable.
Or is it? Exactly how to find out what is available will be left for another post as we do have a tool just for that. But today, just hear me out when I say that binary is often an option even when source is the default. And it matters. See below.
As a (mostly-to-always) Linux user, I sometimes whistle between my teeth that we "lost all those battles" (i.e. for the desktop(s) or laptop(s)) but "won the war". That topic merits a longer post I hope to write one day, and I won't do it justice today but my main gist that everybody (and here I mean mostly developers/power users) now at least also runs on Linux. And by that I mean that we all test our code in Linux environments such as e.g. Travis CI, and that many of us run deployments on cloud instances (AWS, GCE, Azure, ...) which are predominantly based on Linux. Or on local clusters. Or, if one may dream, the top500 And on and on. And frequently these are Ubuntu machines.
So here is an Ubuntu trick: Install from binary, and save loads of time. As an illustration, consider the chart below. It carries over the logic from the 'cached vs non-cached' compilation post and contrasts two ways of installing: from source, or as a binary. I use pristine and empty Docker containers as the base, and rely of course on the official r-base image which is supplied by Carl Boettiger and yours truly as part of our Rocker Project (and for which we have a forthcoming R Journal piece I might mention). So for example the timings for the ggplot2 installation were obtained via
time docker run --rm -ti r-base /bin/bash -c 'install.r ggplot2'and
time docker run --rm -ti r-base /bin/bash -c 'apt-get update && apt-get install -y r-cran-ggplot2'Here docker run --rm -ti just means to launch Docker, in 'remove leftovers at end' mode, use terminal and interactive mode and invoke a shell. The shell command then is, respectively, to install a CRAN package using install.r from my littler package, or to install the binary via apt-get after updating the apt indices (as the Docker container may have been built a few days or more ago).
Let's not focus on Docker here---it is just a convenient means to an end of efficiently measuring via a simple (wall-clock counting) time invocation. The key really is that install.r is just a wrapper to install.packages() meaning source installation on Linux (as used inside the Docker container). And apt-get install ... is how one gets a binary. Again, I will try post another piece to determine how one finds if a suitable binary for a CRAN package exists. For now, just allow me to proceed.
So what do we see then? Well have a look:
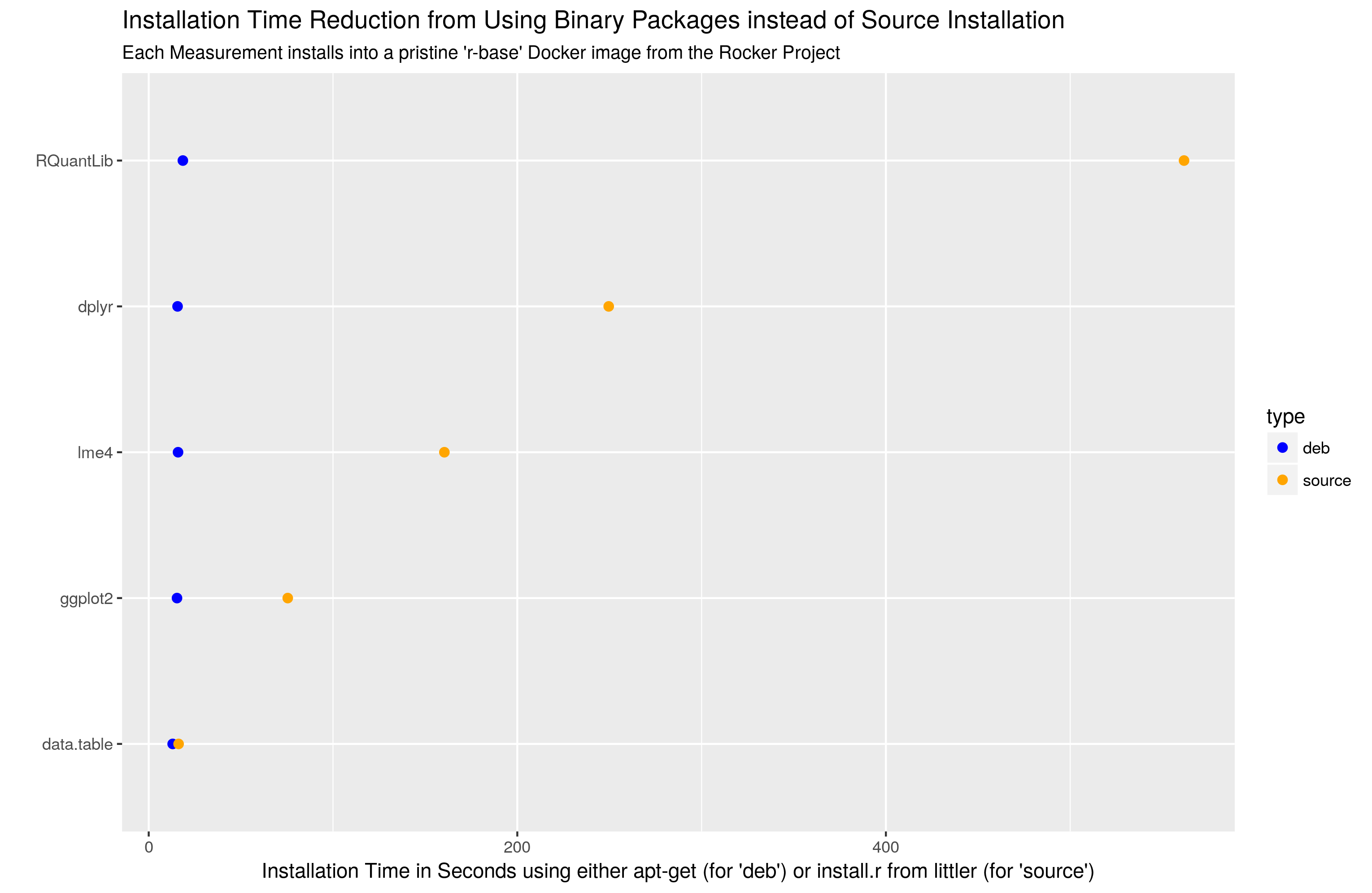
A few things stick out. RQuantLib really is a monster. And dplyr is also fairly heavy---both rely on Rcpp, BH and lots of templating. At the other end, data.table is still a marvel. No external dependencies, and just plain C code make the source installation essentially the same speed as the binary installation. Amazing. But I digress.
We should add that one of the source installations also required installing additional libries: QuantLib is needed along with Boost for RQuantLib. Similar for another package (not shown) which needed curl and libcurl.
So what is the upshot? If you can, consider binaries. I will try to write another post how I do that e.g. for Travis CI where all my tests us binaries. (Yes, I know. This mattered more in the past when they did not cache. It still matters today as you a) do not need to fill the cache in the first place and b) do not need to worry about details concerning compilation from source which still throws enough people off. But yes, you can of course survive as is.)
The same approach is equally valid on AWS and related instances: I answered many StackOverflow questions where folks were failing to compile "large-enough" pieces from source on minimal installations with minimal RAM, and running out of resources and failed with bizarre errors. In short: Don't. Consider binaries. It saves time and trouble.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.